회사에서 처음으로 배치개발을 했다.......
너무 어려웠다...... ㅜㅜㅜ
그래서 시작전 벼락치기 공부한것들을 정리해봤다😁

-
@Configuration
-
spring batch의 모든 job은 @Configruation으로 등록해서 사용합니다.
-
-
jobBuilderFactory.get("simpleJob")
-
simpleJob 이란 이름의 batch job을 생성합니다.
-
job의 이름은 별도로 지정하지 않고 이렇게 builder를 통해 지정합니다.
-
-
stepBuilderFactory.get("simpleStep1")
-
simpleStep1 이란 이름의 batch step을 생성합니다.
-
이것도 마찬가지로 Builder를 통해 이름을 지정합니다.
-
-
.tasklet((contribution, chunkContext))
-
Step 안에서 수행될 기능들을 명시합니다.
-
tasklet은 step안에서 단일로 수행될 커스텀한 기능들을 선언할 때 사용합니다
-
-
batch job을 생성하는 simpleJob 코드를 보시면 simpleStep1을 품고 있음을 알 수 있다.
-
job은 배치 작업 단위를 의미하고 job안에는 여러 step이 존재하고 step안에는 tasklet 또는 reader & processor & writer 묶음이 존재합니다.

-
tasklet 하나와 reader & processor & writer 한 묶음이 같은 레벨입니다.
-
그래서 reader & processor가 끝나고 tasklet으로 마무리를 짓는 등으로 만들 수 없다는 것을 명심
-
tasklet은 spring mvc의 @Component, @Bean과 비슷한 역할이라고 생각
-
tasklet은 spring mvc의 @Component, @Bean과 비슷한 역할이라고 생각
-
- 2. BATCH_JOB_INSTANCE
-
해당 테이블은 job parameter에 따라 생성되는 테이블
-
spring batch가 실행될때 외부에서 받을 수 있는 파라미터로 이 job parameter가 다르면 해당 테이블에 기록되며 같다면 기록되지 않습니다.
- 3. BATCH_JOB_EXECUTION
-
job_execution과 job_instance는 부모-자식 관계입니다.
-
job_execution은 자신의 부모 job_instance가 성공/실패 했던 모든 내역을 갖고 있다.
-
예를들어 동일한 파라미터로 배치를 실행했을 때 한번은 실패 한번은 성공 했을때 !
-
동일한 job parameter로 2번 실행했는데 같은 파라미터로 실행되었다는 에러가 발생하지 않았다.
-
이는 동일한 job parameter로 성공한 기록이 있을때만 재수행이 안된다는 것을 알 수 있다
-
실제 비즈니스 로직을 처리하는 기능은 step에 구현되어 있다.
이처럼 step에서는 batch로 실제 처리하고자 하는 기능과 설정을 모두 포함하는 장소이다.
job 내부의 step들 간의 순서 혹은 처리 흐름을 제어할 필요가 있는데 이번에는 이러한 여러 step들을 어떻게 관리하는지를 알아봅니다.
4. Next

-
보이는 것처럼 next()는 순차적으로 step을 연결시킬때 사용된다.
-
step1 -> step2 -> step3 순으로 하나씩 실행시킬 때 next()는 좋은 방법이다.
-
여기서 중요한 것은!! 앞의 step에서 오류가 나면 나머지 뒤에 있는 step들은 실행되지 못한다는 것이다.
-
하지만 상황에 따라 정상일때는 step b로 오류가 났을때는 step c로 수행해야 될 때가 있다.

-
.on()
-
캐치할 ExitStatus 지정
-
*일 경우 모든 ExitStatus가 지정된다.
-
-
to()
-
다음으로 이동할 step 지정
-
-
from()
-
일종의 이벤트 리스너 역할
-
상태값을 보고 일치하는 상태라면 to에 포함된 step을 호출하게 된다.
-
step1의 이벤트 캐치가 FAILED로 되있는 상태에서 추가로 이벤트를 캐치하려면 from을 써야만 함.
-
-
end()
-
end는 flowbuilder를 반환하는 end와 flowbuilder를 종료하는 end 2개가 있다.
-
on("*") 뒤에 있는 end는 flowbuilder를 반환하는 end
-
build() 앞에 있는 end는 flowbuilder를 종료하는 end
-
flowbuilder를 반환하는 end 사용시 계속해서 from을 이어갈 수 있다.
-
-
여기서 중요한점!! on 이 캐치하는 상태값이 batchstatus가 아닌 exitstatus라는 점이다.
-
그래서 상태값 조정이 필요할때는 exitstatus를 조정해야 한다.
-
contribution.setExitStatus(ExitStatus.FAILED)
-
- 5. Scope
-
외부 혹은 내부에서 파라미터를 받아 여러 batch 컴포넌트에서 사용할 수 있게 지원
-
이러한 파라미터들을 Job parameter라고 한다.
-
job parameter을 사용하기 위해서는 scope를 선언해야만 한다.
-
scope의 종류
-
@StepScope
-
Tasklet이나 ItemReader, ItemWriter, ItemProcessor에서 사용 가능
-
-
@JobScope
-
Step 선언문에서 사용 가능
-
-
-
job parameter 사용법
-
@Value("#{jobParameters[파라미터명]}")
-
double, long, date, string 등이 있다.
-
localdate, localdatetime이 없어 string으로 받아 타입변환을 해서 사용해야 한다.
-
-
@StepScope와 @JobScope 소개
-
spring bean의 기본 scope는 singleton이다.
-
그러나 이처럼 spring batch 컴포넌트(tasklet, itemreader, itemwriter, itemprocessor 등)에 @StepScope를 사용하게 되면 spring batch가 spring 컨테이너를 통해 지정된 step의 실행시점에 해당 컴포넌트를 spring bean으로 생성하게 된다.
-
마찬가지로 @JobScope는 Job 실행시점에 Bean이 생성된다.
-
이렇게 bean의 생성시점을 어플리케이션의 실행 시점이 아닌, step 혹은 job의 실행시점으로 지연시키면서 얻은 장점은 크게 2가지가 있다
-
1) jobparameter의 late binding이 가능하다.
-
job parameter가 stepcontext 또는 jobexecutioncontext 레벨에서 할당시킬 수 있습니다.
-
꼭 application이 실행되는 시점이 아니더라도 controller나, service와 같은 비지니스 로직 처리 단계에서 job parameter를 할당시킬 수 있다.
-
2) 동일한 컴포넌트를 병렬 혹은 동시에 사용할 때 유용하다.
-
step안에 tasklet이 있고 이 tasklet은 멤버 변수와 이 멤버 변수를 변경하는 로직이 있다고 가정해보자.
-
이 경우 @StepScope 없이 Step을 병렬로 실행시키게 되면 서로 다른 step에서 하나의 tasklet을 두고 마구잡이로 상태를 변경하려고 할 것이다.
-
하지만 @StepScope가 있다면 각각의 step에서 별도의 tasklet을 생성하고 관리하기 때문에 서로의 상태를 침범할 일이 없다.
-
-
job parameter의 오해
-
job parameter는 step이나 tasklet, reader 등 batch 컴포넌트 bean의 생성 시점에 호출 할 수 있다. 정확히는 scope bean을 생성할때만 가능하다.
-
즉, @StepScope, @JobScope Bean을 생성할때만 job parameters가 생성되기 때문에 사용할 수 있다.
-
bean을 생성할때 메소드나 클래스 어느 것을 사용해서 생성을 해도 무방하지만 bean의 scope는 반드시 step이나 Job이어야 한다.
-
- 6. Chunk
-
데이터 덩어리로 작업 할때 각 커밋 사이에 처리되는 row수를 이야기 한다.
-
즉 chunk 지향 처리란 한번에 하나씩 데이터를 읽어 chunk라는 덩어리를 만든 뒤, chunk 단위로 트랜잭션을 다루는 것을 의미한다.
-
chunk 단위로 트랜잭션을 수행하기 때문에 실패할 경우엔 해당 chunk만큼만 롤백이 되고 이전에 커밋된 트랜잭션 범위까지는 반영이 된다는 것이다.
-

-
Reader에서 데이터를 하나 읽어온다.
-
읽어온 데이터를 Processor에서 가공한다.
-
가공된 데이터들을 별도의 공간에 모은 뒤, chunk 단위만큼 쌓이게 되면 Writer에 전달하고 Writer는 일괄 저장하게 된다.
-
reader와 processor에서는 1건씩 다뤄지고 wirter에서는 chunk 단위로 처리된다는 것만 기억하면 된다.
-
inputs = chunckProvider.provide(contribution) // reader에서 데이터를 가져온다.
-
reader에서 chunk size 만큼 데이터를 가져온다.
-
-
chunkProcessor.process(contribution, inputs) // processor & writer 처리
-
reader에서 받은 데이터를 가공(processor)하고 저장(writer)한다.
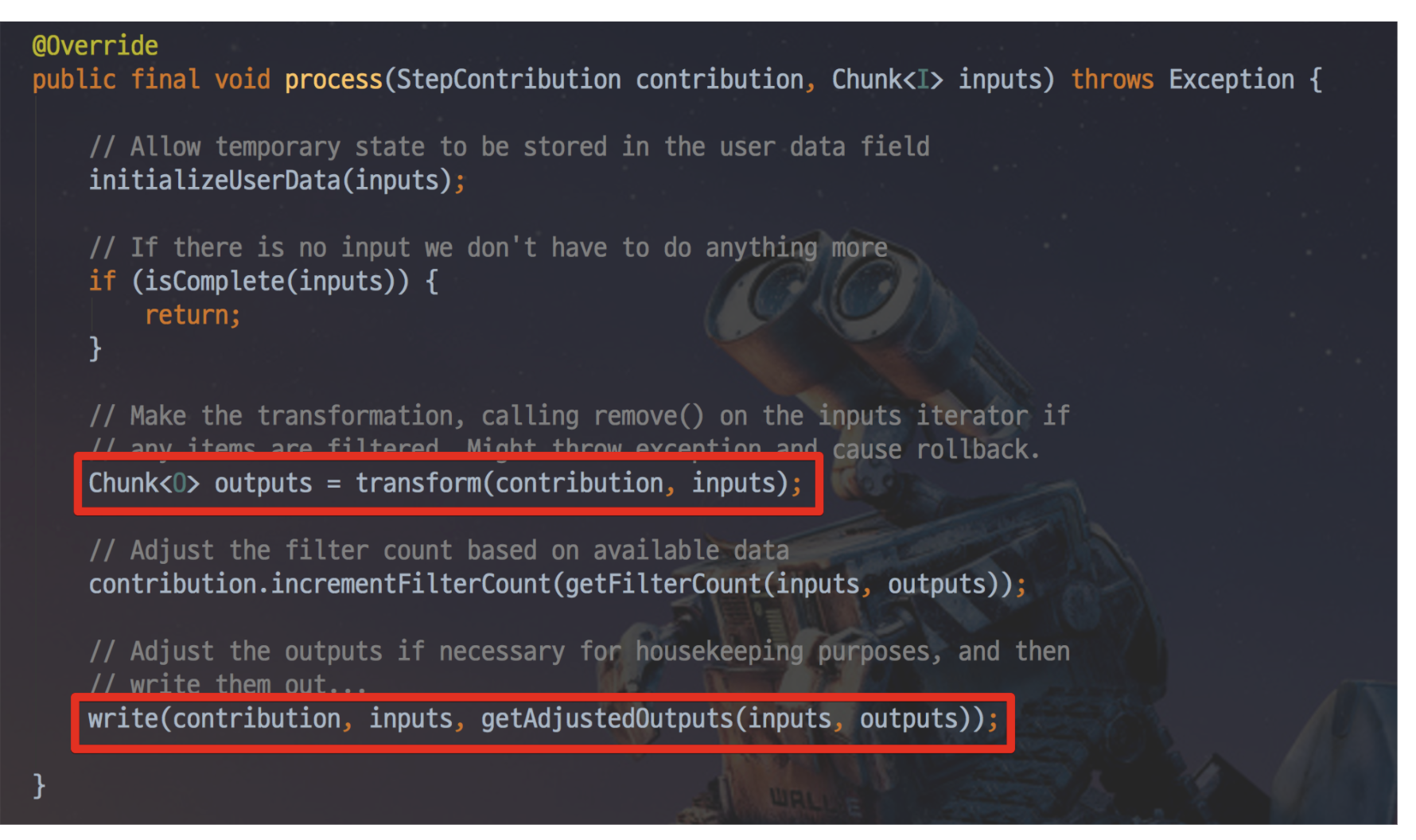
-
inputs를 파라미터로 받습니다.
-
이 데이터는 앞서 chunkprovider.provide()에서 받은 chunksize만큼 쌓인 item입니다.
-
-
transform()에서는 전달받은 inputs을 doProcess()로 전달하고 변환값을 받습니다.
-
transform()을 통해 가공된 대량의 데이터는 wirte()를 통해 일괄 저장됩니다.
-
wirte()는 저장이 될 수도 있고 외부 API로 전송할 수도 있다.
-
이는 개발자마다 다르다.
-
-
-
page size VS chunk size
-
chunk size : 한번에 처리되는 트랜잭션 단위
-
page size : 한번에 조회할 item의 양
-
보통은 성능상의 이슈로 page size와 chunk size를 일치시키는게 좋다.
-
- 7. ItemReader
-
spring batch가 chunk 지향 처리를 하고 있으며 job과 step으로 구성되어 있다.
-
step은 tasklet 단위로 처리되고 있으며, tasklet 중에서 chunkorientedtasklet을 통해 chunk를 처리하며 이를 구성하는 3 요소로 itemReader, itemWriter, itemProcessor가 있음을 배웠다.
-
이 3가지의 묶음 역시 tasklet이며 이들의 묶음을 관리하는 것이 chunkorientedtasklet이다.
-

-
itemReader는 데이터를 읽어들입니다,
-
그게 꼭 DB만의 데이터를 이야기 하진 않고 file, xml, json 등의 다른 데이터 소스를 배치 처리의 입력으로 사용할 수 있다.
-
이외에도 spring batch에서 지원하지 않는 reader가 필요할 경우 직접 해당 reader을 만들 수도 있다.
-
spring batch는 이를 위해 custom reader 구현체를 만들기 쉽게 제공하고 있다.
-
-
itemReader vs itemStream
-
itemReader
-
read() 의 경우 데이터를 읽어오는 메소드이다.
-
-
itemStream
-
주기적으로 상태를 저장하고 오류가 발생하면 해당 상태에서 복원하기 위한 마커 인터페이스이다.
-
즉, itemReader의 상태를 저장하고 실패한 곳에서 다시 실행할 수 있게 해주는 역할이다.
-
open(), close()는 스트림을 열고 닫는다.
-
update()를 사용하면 batch 처리의 상태를 업데이트 할 수 있습니다.
-
-
-
<Pay, Pay> 에서 첫번째 Pay는 Reader에서 반환할 타입이며, 두번째 Pay는 Writer에 파라미터로 넘어올 타입을 얘기합니다.
- 8. ItemWriter
-
spring batch에서 사용하는 출력 기능
-
itemWriter는 item 하나를 작성하지 않고 chunk 단위로 묶인 item list를 다룹니다.
-
그래서 Reader의 read()는 item 하나를 반환하는 반면, Writer의 write()는 인자로 item List를 받습니다.
-
전반적인 PROCESS
-
ItemReader를 통해 각 항목을 개별적으로 읽고 이를 처리하기 위해 itemProcessor에 전달합니다.
-
이 프로세스는 청크의 item 개수 만큼 처리 될 때까지 계속됩니다.
-
청크 단위만큼 처리가 완료되면 Writer에 전달되어 Writer에 명시되어있는대로 일괄처리합니다.
-
즉, reader와 processor를 거쳐 처리된 item을 chunk 단위 만큼 쌓은 뒤 이를 writer에 전달하는 것이다.
-
- 9. ItemProcessor
-
필수가 아니고 데이터를 가공하거나 필터링 하는 역할을 한다.
-
그럼에도 reader와 writer와는 별도의 단계로 분리되었기 때문에 비지니스 코드가 섞이는 것을 방지해준다.
-
Reader에서 넘겨준 데이터 개별건을 가공/처리 해준다.
-
chunksize 단위로 묶은 데이터를 한번에 처리하는 itemWrtier와는 대조적이다.
-
-
ItemProcessor를 사용하는 방법 2가지
- 변환
-
Reader에서 읽은 데이터를 원하는 타입으로 변환해서 Wrtier에 넘겨주는 것
-
- 필터
-
Reader에서 넘겨준 데이터를 Writer로 넘겨줄 것인지를 결정
-
null을 반환할 경우 writer에 전달되지 않는다.
-
- 변환
-
기본 사용법

-
I : itemReader에서 받을 데이터 타입
-
O:itemWriter에 보낼 데이터 타입
-
Reader에서 읽은 데이터가 itemProcessor의 process를 통과해서 Writer에 전달됩니다.
-
그래서 구현해야 할 메소드는 process 하나입니다.
-
자바 8부터는 인터페이스의 추상 메소드가 1개일 경우에는 람다를 사용할 수 있기때문에 process() 역시 람다식을 사용할 수 있습니다.
'배움 기록_실무 ✏️' 카테고리의 다른 글
| 구글 OAuth2 인증 방식 (0) | 2022.03.29 |
|---|---|
| OAuth 동작 방식 (1) | 2022.03.29 |
| 쿠팡 파트너스 API 연동 (2) | 2022.02.28 |
| JWT에 대해서 (1) | 2022.01.10 |
| AWS SQS (1) | 2021.04.16 |